隨著人工智能浪潮席卷全球,中國大模型產業正站在關鍵的十字路口。開源與閉源,這兩條截然不同的技術路線,不僅代表了不同的技術哲學與生態策略,更深刻地影響著國產大模型在研發、生態構建以及商業化落地等多個維度的未來走向。在這場路線之爭的背后,是國產大模型如何突破技術壁壘、構建可持續商業模式的深刻挑戰。
一、開源與閉源:兩條道路,兩種生態
開源路徑以透明、協作、快速迭代為核心優勢。國內如智譜AI、百川智能等公司已推出系列開源模型,通過開放模型權重和代碼,極大地降低了行業技術門檻,促進了學術研究、中小企業創新以及廣泛的應用開發。開源生態能夠加速技術擴散,匯聚社區智慧,快速形成基于主流模型的工具鏈和中間件,有助于在短期內構建活躍的開發者生態。開源路線也面臨挑戰:如何確保持續的、高質量的研發投入?如何建立有效的商業模式,將技術影響力轉化為商業收益?
閉源路徑則強調技術壁壘、商業控制與差異化服務。以百度文心、阿里通義等為代表的閉源模型,通常在企業級服務、深度定制和復雜場景應用中展現出優勢。通過閉源,企業能更好地保護核心技術,打造產品護城河,并通過API調用、私有化部署等模式直接實現盈利。其挑戰在于,在日益激烈的全球競爭中,如何保持技術領先性?如何應對開源社區快速迭代帶來的競爭壓力?
二、網絡技術研發:基礎決定高度
無論選擇何種路線,底層網絡技術的研發都是大模型能力的基石。這包括:
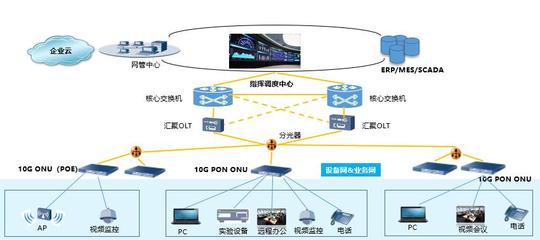
- 算力基礎設施:面對高端芯片的獲取限制,國產算力(如昇騰、海光等)的軟硬件協同優化、大規模集群的穩定訓練與高效調度,是必須攻克的核心難關。
- 算法與架構創新:在Transformer等主流架構基礎上,探索更高效、更節能的模型架構(如MoE混合專家模型),研究訓練與推理的優化技術,是提升性能、降低成本的關鍵。
- 數據工程與治理:構建高質量、多元化、合規的中文及多語言數據集,并發展高效的數據清洗、標注與合成技術,是模型“智慧”的源泉。
三、商業化挑戰:尋找可持續的“造血”模式
國產大模型的商業化之路,遠比對標技術指標更為復雜:
- 市場定位與需求洞察:通用大模型能力雖強,但企業客戶更需要能解決具體業務痛點(如營銷文案生成、代碼輔助、客服質檢)的垂直化、專業化解決方案。如何從“技術炫技”轉向“價值落地”,是商業化的首要命題。
- 成本與定價的平衡:大模型的訓練與推理成本高昂。如何在提供有競爭力價格的覆蓋巨額研發和算力成本,并實現盈利,是商業模式設計的核心。開源模型可通過支持服務、云平臺、企業版授權等方式變現;閉源模型則需證明其API服務或私有化部署能為客戶創造顯著超額價值。
- 生態構建與標準競爭:大模型的競爭本質是生態的競爭。無論是通過開源聚集開發者,還是通過閉源綁定核心合作伙伴,構建一個繁榮的應用生態和工具鏈,并爭取在行業標準中的話語權,是確立長期競爭優勢的戰略要地。
- 安全、合規與可信賴:隨著監管框架的完善,數據安全、隱私保護、內容合規以及算法的可解釋性與公平性,已成為產品進入核心行業(如金融、政務、醫療)的準入門檻。
四、未來展望:融合共生與差異化競爭
國產大模型的路線之爭未必是非此即彼的零和博弈,更可能走向一種動態的融合與共生:
- 分層生態:可能出現“基礎模型開源,高級功能/服務閉源”的混合模式,或由頭部企業提供閉源核心模型,同時培育圍繞其的開源工具和應用生態。
- 場景深潛:在通用能力之外,在智能制造、生物醫藥、科學計算等特定領域,基于深度領域知識(可能結合開源或閉源基礎模型)打造的專業模型,將成為重要的價值突破點。
- 協同創新:在關鍵的網絡技術研發上,如算力集群技術、訓練框架、評測基準等,國內企業、科研機構乃至開源社區,存在廣闊的協同創新空間,以共同突破基礎性瓶頸。
國產大模型的征程是一場技術、生態與商業的馬拉松。開源與閉源是工具和路徑,而非目的。最終的成功,將屬于那些能夠將技術創新與深刻的產業洞察相結合,在堅實的網絡技術研發基礎上,構建出可持續、可盈利且能創造真實價值的商業模式的企業。這場路線之爭的結果,將深刻塑造中國在全球人工智能格局中的位置與角色。